Data Science Experience Platform
As a part of IBM’s Analytics Platform, my team created a data modeling SaaS for Data Scientists. We focused on the “canvas” portion of the software, which is a flexible, collaborative GUI-to-code interface for data modeling.
My main responsibilities were to clarify our target persona, engage with users for feedback, and create UX designs based on research insights. I also led the creation of 2-week design/research sprint cycles, which was recognized and shared internally.
Below, I’ve included some of my research and design artifacts that hint at how we converged on our designs. However, I’ve had to emit a great deal of material due to IBM’s NDA. Please reach out and I would be happy to share more details on the experience and skills that I gained while creating the Canvas Modeling UX.
Role
UX design
User research
Team
Visual designer
Front-end prototyper
Engineers
Product manager

Problem: shortage of data scientists
In the last 5-6 years, the demand for businesses to leverage data-driven insights has increased exponentially. Yet because data science is still a new domain, there is a shortage of seasoned data scientists who can create advanced analytical models. This trend has encouraged people with math, business and computer science backgrounds to transition into data science roles. However, their limited knowledge working in code (RStudios and/or Python) limits them from creating and exploring a wide breadth of advanced analytical models.

6 out of 10 companies provide in house training for employees to do data science
Source: MIT Sloan Mangement Review survey of 2,710 business executives, managers and analytics professionals worldwide.
Solution: enable emerging data scientists
The ultimate vision of the “canvas” is to provide data science teams with an intuitive GUI to work collaboratively and create advanced analytical models (import and transform data, apply algorithms, create models, and deploy the models) without having to spend any time working in code.
Early Concept
Legacy Product: SPSS Modeler
IBM currently offers a similar product called the SPSS modeler, a clunky but robust on-prem GUI for advanced data modeling. The canvas took technical capabilities of the SPSS Modeler, and redesigned the UX starting with a thorough understanding of data scientists' needs.

SPSS Modeler
Cross Platform Research
User Research
I collaborated with product designers and researchers on the Analytics platform, engaging with the data science community. My role involved user recruitment, planning research activities, and conducting interviews with data scientists at various institutions, including the University of Texas, Galvanize, Meetups, and Verizon. Methods included contextual observations, in-person and phone interviews, and surveys.

Defining Personas
Our team’s first challenge was to define our products' personas. Our persona lay somewhere between the data scientist and business analyst. From our initial research, we found that there was an ambiguous line distinguishing the roles of data scientist versus a business analyst in the field of data analytics.



Data Scientist Development Stages

Early Career
Either currently in or recently graduated from a masters or immersive Data Science program.
Relatively lower skill level and tends to be relatively equal in the aspects of math, computing, and business.
Transitioning
Transitioning into data science from a business analytics background or from an engineering background.
Many companies support this transition in their employees since they already have domain knowledge.
Practicing
Stronger math or quantitative background.
Proficient in computing as well. There are some who are stronger on the computing side.
Data Science Process
The data science process is an iterative process like any scientific experiment. It requires data scientists to test their hypothesis, change variables, log outcomes, and iterate accordingly. Depending on the size of the organization, data science teams can range from 1-10 members. Some data scientists will cover the end to end data science process alone or collaborate with data engineers and business analysts.

DSX Canvas's Focus

Data Science Pain Points
IBM Internal and Competitors' Offerings Research
We researched competitors offerings and also regularly met with two of IBM's expert data scientists to understand and break down the capabilities of SPSS Modeler, an IBM legacy product offering GUI for advanced data modeling.
SPSS Modeler Heuristic Evaluation

SPSS Modeler
Competitor Offerings Evaluation

Design Principles Based on User Research
We used these design tenets as guiding principles for making design decisions, and further validated our ideas through user testing.






Biweekly Research Sprints
An essential part of our design process was managing agile internal collaboration with the research, design, dev team and offering managers. Close collaboration with offering managers ensured understanding of business goals, while engagement with developers validated tech feasibility. I spearheaded a two-week research sprint cycle, recognized internally and shared with all design researchers. This approach established a consistent cadence aligning business goals, user needs, and technical feasibility.
Canvas Design Opportunities
-
Collaborative for data science teamwork
-
Flexible for iterative experimentation
-
Clarity for navigating complex workflows
Key Feature of DSX Canvas
-
Node designs
-
Tools palette
-
Node settings editor designs
-
Commenting on canvas
-
Canvas search
-
Error states
Node Interactions
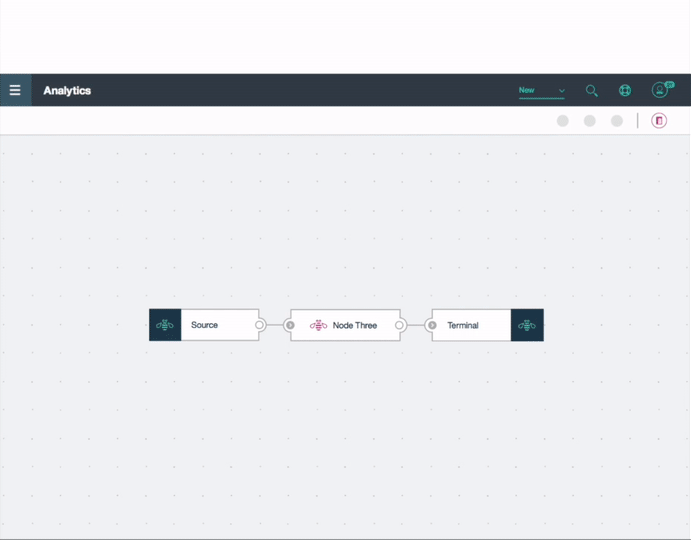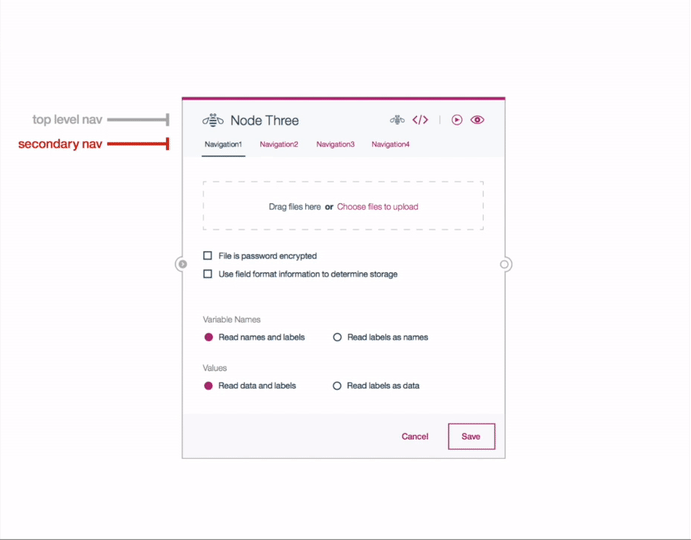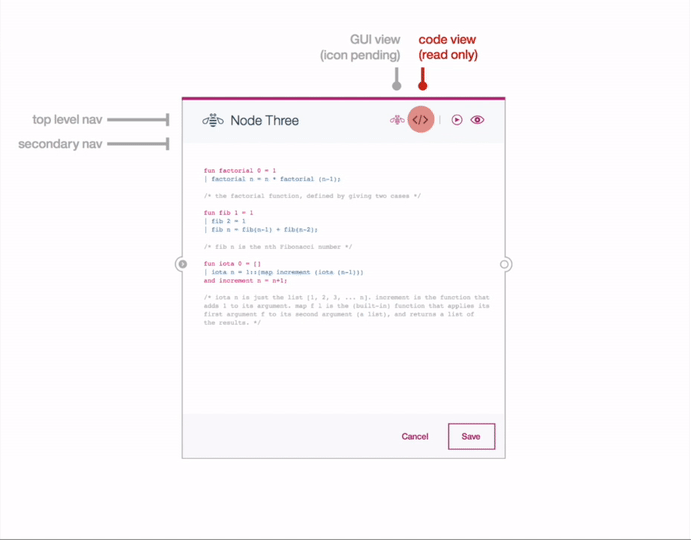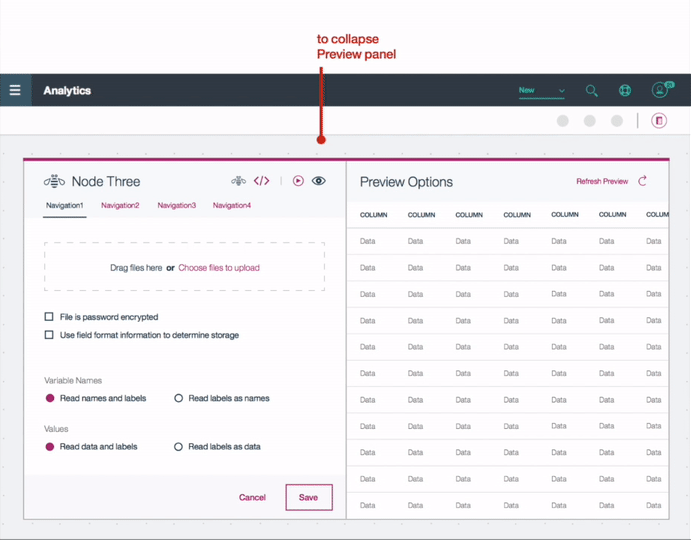
Based on technical research, we identified three node types: input, intermediate, and output. To enhance user clarity, we explored distinct variations for easy differentiation between data, algorithm, and output model nodes. Addressing data scientists' skepticism of black box data, transparency was a key design consideration. Connecting nodes and processing results, we prioritized user control by ensuring visible progress status.




Tool Palette
The tool palette design was crucial for maximizing canvas screen space for experimentation. We considered options like a sliding palette from the right-side navigation and a flexible, draggable tool palette. Accessibility and quick interaction were prioritized as users frequently engage with it. User testing emphasized flexibility for data scientists, promoting creative iteration. The chosen design is a flexible tool palette, accessible by clicking the palette icon, with tools categorized by capabilities and a section for recently used nodes.






Editor Settings
My team and I reviewed around 90 nodes in the SPSS Modeler, identifying common patterns in node editor settings. We designed a template for the editors, so that the developer could populate them with the settings for the individual nodes. User testing revealed users open multiple editor dialogues simultaneously for comparison. Recognizing the need for context in viewing connected nodes, we designed editors to expand upon clicking a node, providing visibility into connected nodes.
Evaluative Research: User Feedback, Surveys, Usability Tests
We created multiple iterations of lo-fi to mid-fi wireframes. In our 2 week design sprints, we looped in user feedback through recurring usability tests.


Open Beta Canvas on IBM Data Science Experience
The integration of SPSS Modeler "canvas" in the Data Science Experience was announced at the 2016 World of Watson conference. The canvas is available as open BETA on the IBM Data Science Experience Platform.
Key Learnings
-
Launched agile design sprints for the entire team.
-
Explored pros and cons of working in agile sprints.
-
Effectively communicated with dev and PM teams to align with their needs and business objectives.
-
Developed the ability to stay focused while navigating through ambiguity.
-
Acknowledged that a business-driven UX process is nonlinear.
-
Established trust and confidence with internal stakeholders through user research.
-
Realized UX design extends beyond interfaces, encompassing understanding relationships within the company and core business objectives.
Challenges
-
Silo-ed and dispersed teams- research, design, dev, PM
-
High learning curve to overcome technical domain knowledge
-
Lack of clarity on business objectives
-
Disconnected research and design goals
-
Unanswered questions and assumptions about our users
Overcoming Challenges
-
Providing research driven design guidance to new DSX canvas
-
Implementing agile sprints and evangelizing sprint process across DSX product teams
-
Positive feedback from data scientists for the new SPSS Modeler
-
Increased understanding of user centric design processes across PM and dev team while working on the next project, Watson Machine Learning/Deep Learning.